从一次经历谈 TIME_WAIT 的那些事
 今天来讲一讲TCP 的
今天来讲一讲TCP 的 TIME_WAIT 的问题。这个问题尽人皆知,不过,这次遇到的是不太一样的场景,前两天也解决了,正好写篇文章,顺便把 TIME_WAIT 的那些事都说一说。对了,这个场景,跟我开源的探活小工具 EaseProbe 有关,我先说说这个场景里的问题,然后,顺着这个场景跟大家好好说一下这个事。
目录
问题背景
先说一下背景,EaseProbe 是一个轻量独立的用来探活服务健康状况的小工具,支持http/tcp/shell/ssh/tls/host以及各种中间件的探活,然后,直接发送通知到主流的IM上,如:Slack/Telegram/Discrod/Email/Team,包括国内的企业微信/钉钉/飞书, 非常好用,用过的人都说好 😏。
这个探活工具在每次探活的时候,必须要从头开始建立整个网络链接,也就是说,需要从头开始进行DNS查询,建立TCP链接,然后进行通信,再关闭链接。这里,我们不会设置 TCP 的 KeepAlive 重用链接,因为探活工具除了要探活所远端的服务,还要探活整个网络的情况,所以,每次探活都需要从新来过,这样才能捕捉得到整个链路的情况。
但是,这样不断的新建链接和关闭链接,根据TCP的状态机,我们知道这会导致在探测端这边出现的 TIME_WAIT 的 TCP 链接,根据 TCP 协议的定义,这个 TIME_WAIT 需要等待 2倍的MSL 时间,TCP 链接都会被系统回收,在回收之前,这个链接会占用系统的资源,主要是两个资源,一个是文件描述符,这个还好,可以调整,另一个则是端口号,这个是没法调整的,因为作为发起请求的client来说,在对同一个IP上理论上你只有64K的端口号号可用(实际上系统默认只有近30K,从32,768 到 60,999 一共 60999+1-32768=28,232,你可以通过 sysctl net.ipv4.ip_local_port_range 查看 ),如果 TIME_WAIT 过多,会导致TCP无法建立链接,还会因为资源消耗太多导致整个程序甚至整个系统异常。
试想,如果我们以 10秒为周期探测10K的结点,如果TIME_WAIT的超时时间是120秒,那么在第60秒后,等着超时的 TIME_WAIT 我们就有可能把某个IP的端口基本用完了,就算还行,系统也有些问题。(注意:我们不仅仅只是TCP,还有HTTP协议,所以,大家不要觉得TCP的四元组只要目标地址不一样就好了,一方面,我们探的是域名,需要访问DNS服务,所以,DNS服务一般是一台服务器,还有,因为HTTPS一般是探API,而且会有网关代理API,所以链接会到同一个网关上。另外就算还可以建出站连接,但是本地程序会因为端口耗尽无法bind了。所以,现实情况并不会像理论情况那样只要四元组不冲突,端口就不会耗尽)
为什么要 TIME_WAIT
那么,为什么TCP在 TIME_WAIT 上要等待一个2MSL的时间?
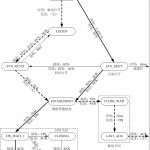
以前写过篇比较宏观的《TCP的那些事》(上篇,下篇),这个访问在“上篇”里讲过,这里再说一次,TCP 断链接的时候,会有下面这个来来回回的过程。
我们来看主动断链接的最后一个状态 TIME_WAIT 后就不需要等待对端回 ack了,而是进入了超时状态。这主要是因为,在网络上,如果要知道我们发出的数据被对方收到了,那我们就需要对方发来一个确认的Ack信息,那问题来了,对方怎么知道自己发出去的ack,被收到了?难道还要再ack一下,这样ack来ack回的,那什么谁也不要玩了……是的,这就是比较著名的【两将军问题】——两个将军需要在一个不稳定的信道上达成对敌攻击时间的协商,A向B派出信鸽,我们明早8点进攻,A怎么知道B收到了信?那需要B向A派出信鸽,ack说我收到了,明早8点开干。但是,B怎么知道A会收到自己的确认信?是不是还要A再确认一下?这样无穷无尽的确认导致这个问题是没有完美解的(我们在《分布式事务》一文中说过这个问题,这里不再重述)
所以,我们只能等一个我们认为最大小时来解决两件个问题:
1) 为了 防止来自一个连接的延迟段被依赖于相同四元组(源地址、源端口、目标地址、目标端口)的稍后连接接受(被接受后,就会被马上断掉,TCP状态机紊乱)。虽然,可以通过指定 TCP 的 sequence number 一定范围内才能被接受。但这也只是让问题发生的概率低了一些,对于一个吞吐量大的的应用来说,依然能够出现问题,尤其是在具有大接收窗口的快速连接上。RFC 1337详细解释了当 TIME-WAIT状态不足时会发生什么。TIME-WAIT以下是如果不缩短状态可以避免的示例:

2)另一个目的是确保远端已经关闭了连接。当最后一个ACK 丢失时,对端保持该LAST-ACK状态。在没有TIME-WAIT状态的情况下,可以重新打开连接,而远程端仍然认为先前的连接有效。当它收到一个SYN段(并且序列号匹配)时,它将以RST应答,因为它不期望这样的段。新连接将因错误而中止:

TIME_WAIT 的这个超时时间的值如下所示:
- 在 macOS 上是15秒,
sysctl net.inet.tcp | grep net.inet.tcp.msl - 在 Linux 上是 60秒
cat /proc/sys/net/ipv4/tcp_fin_timeout
解决方案
要解决这个问题,网上一般会有下面这些解法
- 把这个超时间调小一些,这样就可以把TCP 的端口号回收的快一些。但是也不能太小,如果流量很大的话,TIME_WAIT一样会被耗尽。
- 设置上
tcp_tw_reuse。RFC 1323提出了一组 TCP 扩展来提高高带宽路径的性能。除其他外,它定义了一个新的 TCP 选项,带有两个四字节时间戳字段。第一个是发送选项的 TCP 时间戳的当前值,而第二个是从远程主机接收到的最新时间戳。如果新时间戳严格大于为前一个连接记录的最新时间戳。Linux 将重用该状态下的现有TIME_WAIT连接用于出站的链接。也就是说,这个参数对于入站连接是没有任何用图的。 - 设置上
tcp_tw_recycle。 这个参数同样依赖于时间戳选项,但会影响进站和出站链接。这个参数会影响NAT环境,也就是一个公司里的所有员工用一个IP地址访问外网的情况。在这种情况下,时间戳条件将禁止在这个公网IP后面的所有设备在一分钟内连接,因为它们不共享相同的时间戳时钟。毫无疑问,禁用此选项要好得多,因为它会导致 难以检测和诊断问题。(注:从 Linux 4.10 (commit 95a22caee396 ) 开始,Linux 将为每个连接随机化时间戳偏移量,从而使该选项完全失效,无论有无NAT。它已从 Linux 4.12中完全删除)
对于服务器来说,上述的三个访问都不能解决服务器的 TIME_WAIT 过多的问题,真正解决问题的就是——不作死就不会死,也就是说,服务器不要主动断链接,而设置上KeepAlive后,让客户端主动断链接,这样服务端只会有CLOSE_WAIT。
但是对于用于建立出站连接的探活的 EaseProbe来说,设置上 tcp_tw_reuse 就可以重用 TIME_WAIT 了,但是这依然无法解决 TIME_WAIT 过多的问题。
然后,过了几天后,我忽然想起来以前在《UNIX 网络编程》上有看到过一个Socket的参数,叫 <code>SO_LINGER,我的编程生涯中从来没有使用过这个设置,这个参数主要是为了延尽关闭来用的,也就是说你应用调用 close()函数时,如果还有数据没有发送完成,则需要等一个延时时间来让数据发完,但是,如果你把延时设置为 0 时,Socket就丢弃数据,并向对方发送一个 RST 来终止连接,因为走的是 RST 包,所以就不会有 TIME_WAIT 了。
这个东西在服务器端永远不要设置,不然,你的客户端就总是看到 TCP 链接错误 “connnection reset by peer”,但是这个参数对于 EaseProbe 的客户来说,简直是太完美了,当EaseProbe 探测完后,直接 reset connection, 即不会有功能上的问题,也不会影响服务器,更不会有烦人的 TIME_WAIT 问题。
Go 实际操作
在 Golang的标准库代码里,net.TCPConn 有个方法 SetLinger()可以完成这个事,使用起来也比较简单:
conn, _ := net.DialTimeout("tcp", t.Host, t.Timeout())
if tcpCon, ok := conn.(*net.TCPConn); ok {
tcpCon.SetLinger(0)
}
你需要把一个 net.Conn 转型成 net.TCPConn,然后就可以调用方法了。
但是对于Golang 的标准库中的 HTTP 对象来说,就有点麻烦了,Golang的 http 库把底层的这边连接对象全都包装成私有变量了,你在外面根本获取不到。这篇《How to Set Go net/http Socket Options – setsockopt() example 》中给出了下面的方法:
dialer := &net.Dialer{
Control: func(network, address string, conn syscall.RawConn) error {
var operr error
if err := conn.Control(func(fd uintptr) {
operr = syscall.SetsockoptInt(int(fd), unix.SOL_SOCKET, unix.TCP_QUICKACK, 1)
}); err != nil {
return err
}
return operr
},
}
client := &http.Client{
Transport: &http.Transport{
DialContext: dialer.DialContext,
},
}
上面这个方法非常的低层,需要直接使用setsocketopt这样的系统调用,我其实,还是想使用 TCPConn.SetLinger(0) 来完成这个事,即然都被封装好了,最好还是别破坏封闭性碰底层的东西。
经过Golang http包的源码阅读和摸索,我使用了下面的方法:
client := &http.Client{
Timeout: h.Timeout(),
Transport: &http.Transport{
TLSClientConfig: tls,
DisableKeepAlives: true,
DialContext: func(ctx context.Context, network, addr string) (net.Conn, error) {
d := net.Dialer{Timeout: h.Timeout()}
conn, err := d.DialContext(ctx, network, addr)
if err != nil {
return nil, err
}
tcpConn, ok := conn.(*net.TCPConn)
if ok {
tcpConn.SetLinger(0)
return tcpConn, nil
}
return conn, nil
},
},
}
然后,我找来了全球 T0p 100W的域名,然后在AWS上开了一台服务器,用脚本生成了 TOP 10K 和 20K 的网站来以5s, 10s, 30s, 60s的间隔进行探活,搞到Cloudflare 的 1.1.1.1 DNS 时不时就把我拉黑,最后的测试结果也非常不错,根本 没有 TIME_WAIT 的链接,相关的测试方法、测试数据和测试报告可以参看:Benchmark Report
总结
下面是几点总结
TIME_WAIT是一个TCP 协议完整性的手段,虽然会有一定的副作用,但是这个设计是非常关键的,最好不要妥协掉。- 永远不要使用
tcp_tw_recycle,这个参数是个巨龙,破坏力极大。 - 服务器端永远不要使用
SO_LINGER(0),而且使用tcp_tw_reuse对服务端意义不大,因为它只对出站流量有用。 - 在服务端上最好不要主动断链接,设置好KeepAlive,重用链接,让客户端主动断链接。
- 在客户端上可以使用
tcp_tw_reuse和SO_LINGER(0)。
最后强烈推荐阅读这篇文章 – Coping with the TCP TIME-WAIT state on busy Linux servers
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)






 (52 人打了分,平均分: 4.56 )
(52 人打了分,平均分: 4.56 )
《从一次经历谈 TIME_WAIT 的那些事》的相关评论
看完了,感觉又像什么也没看,能力不够,我需要多学习
点了右上角的 High 一下,好有意思,,哈哈哈
多学习就好了,刚开始都是不懂的
hahha +1+1
“支持http/tcp/shell/ssh/tls/host以及各种中间件的控活”
控活是什么意思呢?
我猜测可能是“探活”。
永完不要使用—> 永远
“上面这个方法非常的低层,需要直接使用setsocketopt这样的系统调用,我其实,还是想使用 TCPConn.SetLinger(0) 来完成这个事,我不是很难碰底层的事。”这里是想写“我不是很想”么?
“ 试想,如果我们以 10秒为周期探测10K的结点,如果TIME_WAIT的超时时间是120秒,那么在第60秒后,等着超时的 TIME_WAIT 我们就有可会把端口基本用完了。 ”
tcp连接是五元组,本地端口的数量限制是对同一目的ip+目的端口,这里探测10k节点,如果是指10k不同的目的ip、端口元组,应该还不会出现无端口可用的问题?
文中有提到,还有dns的问题, 探测的时候可能要先经过dns, 这一步就已经会遇到同一个目标的问题.
linger选项比较常用吧,为啥不让在服务端用?比如非法连接长时间占用资源,不发数据或者发些非协议随机数据
Team -> Teams
用图 -> 用途
linger close,作为直接面临公网的服务端,还是挺经常遇到的,防攻击、封禁等等场景,一般都会用linger close
the net.ipv4.tcp_tw_recycle option is quite problematic for public-facing servers as it won’t handle connections from two different computers behind the same NAT device, which is a problem hard to detect and waiting to bite you:
被咬了不止一次了
使用SO_REUSEADDR是不是也能解决问题?
写的挺好,虽然看不完全懂,但大受震撼,期待以后继续
看不懂先从找错别字开始哈哈哈哈
“我不是很难碰底层的事。”这句话没看明白。是“不是很愿意”么
谢谢,原意是,因为都被封装好,所以,最好不要破坏封装裸用底层的东西。我修改了一下描述。
“永远不要使用 tcp_tw_recycle ,这个参数是个巨龙,破坏力极大”,如果已经在巨龙上了, 是否真的要屠龙?
写的很好,愈来愈浮躁的行业需要这样的底层技术细节文章。
看有些资料上面说/proc/sys/net/ipv4/tcp_fin_timeout这个参数不能控制TIME_WAIT的时长,TIME_WAIT的时长是靠内核中的一个宏定义来控制的,是这样的吗?陈老师
这么多年了,你的博客一直更新,真是不简单。
想看耗子哥讲ddd,或者面对复杂业务时的建模思考
为啥这篇文章没在rss里出现呢
这个参数对于入站连接是没有任何用图的
用图–>用途
像nmap这样的扫描工具,SO_LINGER都是标配