无锁HashMap的原理与实现
(本文由onetwogoo投稿)
在《疫苗:Java HashMap的死循环》中,我们看到,java.util.HashMap并不能直接应用于多线程环境。对于多线程环境中应用HashMap,主要有以下几种选择:
- 使用线程安全的java.util.Hashtable作为替代。
- 使用java.util.Collections.synchronizedMap方法,将已有的HashMap对象包装为线程安全的。
- 使用java.util.concurrent.ConcurrentHashMap类作为替代,它具有非常好的性能。
而以上几种方法在实现的具体细节上,都或多或少地用到了互斥锁。互斥锁会造成线程阻塞,降低运行效率,并有可能产生死锁、优先级翻转等一系列问题。
CAS(Compare And Swap)是一种底层硬件提供的功能,它可以将判断并更改一个值的操作原子化。关于CAS的一些应用,《无锁队列的实现》一文中有很详细的介绍。
目录
Java中的原子操作
在java.util.concurrent.atomic包中,Java为我们提供了很多方便的原子类型,它们底层完全基于CAS操作。
例如我们希望实现一个全局公用的计数器,那么可以:
private AtomicInteger counter = new AtomicInteger(3);
public void addCounter() {
for (;;) {
int oldValue = counter.get();
int newValue = oldValue + 1;
if (counter.compareAndSet(oldValue, newValue))
return;
}
}
其中,compareAndSet方法会检查counter现有的值是否为oldValue,如果是,则将其设置为新值newValue,操作成功并返回true;否则操作失败并返回false。
当计算counter新值时,若其他线程将counter的值改变,compareAndSwap就会失败。此时我们只需在外面加一层循环,不断尝试这个过程,那么最终一定会成功将counter值+1。(其实AtomicInteger已经为常用的+1/-1操作定义了incrementAndGet与decrementAndGet方法,以后我们只需简单调用它即可)
除了AtomicInteger外,java.util.concurrent.atomic包还提供了AtomicReference和AtomicReferenceArray类型,它们分别代表原子性的引用和原子性的引用数组(引用的数组)。
无锁链表的实现
在实现无锁HashMap之前,让我们先来看一下比较简单的无锁链表的实现方法。
以插入操作为例:
- 首先我们需要找到待插入位置前面的节点A和后面的节点B。
- 然后新建一个节点C,并使其next指针指向节点B。(见图1)
- 最后使节点A的next指针指向节点C。(见图2)
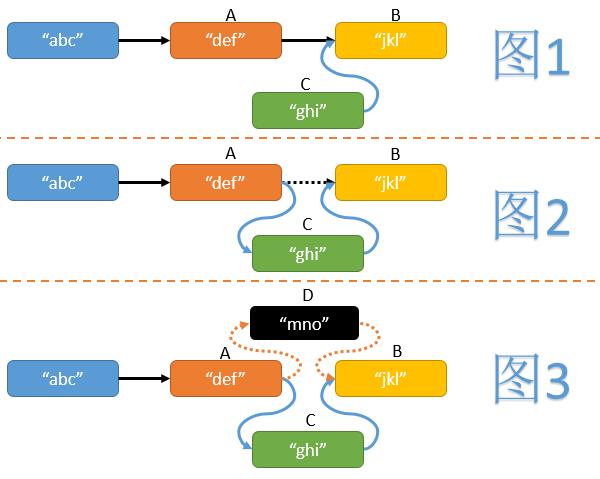
但在操作中途,有可能其他线程在A与B直接也插入了一些节点(假设为D),如果我们不做任何判断,可能造成其他线程插入节点的丢失。(见图3)我们可以利用CAS操作,在为节点A的next指针赋值时,判断其是否仍然指向B,如果节点A的next指针发生了变化则重试整个插入操作。大致代码如下:
private void listInsert(Node head, Node c) {
for (;;) {
Node a = findInsertionPlace(head), b = a.next.get();
c.next.set(b);
if (a.next.compareAndSwap(b,c))
return;
}
}
(Node类的next字段为AtomicReference<Node>类型,即指向Node类型的原子性引用)
无锁链表的查找操作与普通链表没有区别。而其删除操作,则需要找到待删除节点前方的节点A和后方的节点B,利用CAS操作验证并更新节点A的next指针,使其指向节点B。
无锁HashMap的难点与突破
HashMap主要有插入、删除、查找以及ReHash四种基本操作。一个典型的HashMap实现,会用到一个数组,数组的每项元素为一个节点的链表。对于此链表,我们可以利用上文提到的操作方法,执行插入、删除以及查找操作,但对于ReHash操作则比较困难。
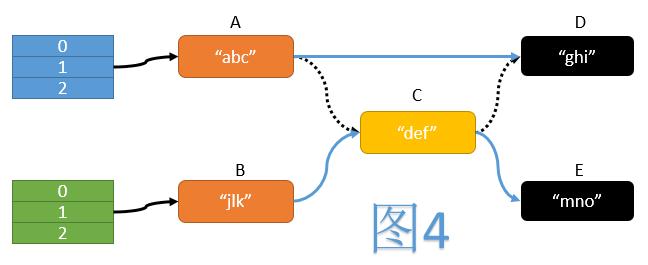
如图4,在ReHash过程中,一个典型的操作是遍历旧表中的每个节点,计算其在新表中的位置,然后将其移动至新表中。期间我们需要操纵3次指针:
- 将A的next指针指向D
- 将B的next指针指向C
- 将C的next指针指向E
而这三次指针操作必须同时完成,才能保证移动操作的原子性。但我们不难看出,CAS操作每次只能保证一个变量的值被原子性地验证并更新,无法满足同时验证并更新三个指针的需求。
于是我们不妨换一个思路,既然移动节点的操作如此困难,我们可以使所有节点始终保持有序状态,从而避免了移动操作。在典型的HashMap实现中,数组的长度始终保持为2i,而从Hash值映射为数组下标的过程,只是简单地对数组长度执行取模运算(即仅保留Hash二进制的后i位)。当ReHash时,数组长度加倍变为2i+1,旧数组第j项链表中的每个节点,要么移动到新数组中第j项,要么移动到新数组中第j+2i项,而它们的唯一区别在于Hash值第i+1位的不同(第i+1位为0则仍为第j项,否则为第j+2i项)。
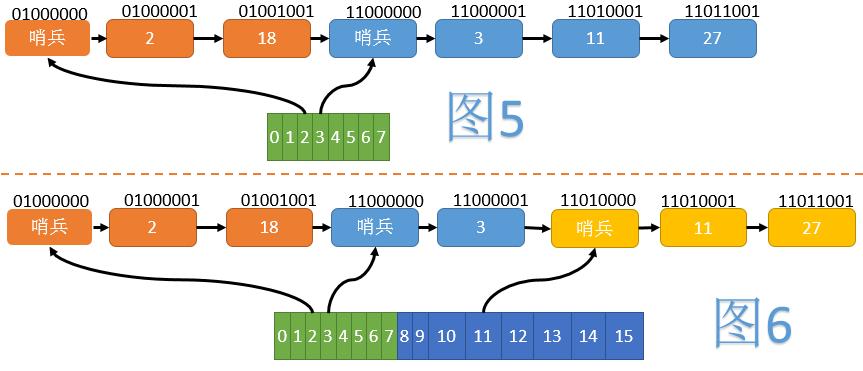
如图5,我们将所有节点按照Hash值的翻转位序(如1101->1011)由小到大排列。当数组大小为8时,2、18在一个组内;3、11、27在另一个组内。每组的开始,插入一个哨兵节点,以方便后续操作。为了使哨兵节点正确排在组的最前方,我们将正常节点Hash的最高位(翻转后变为最低位)置为1,而哨兵节点不设置这一位。
当数组扩容至16时(见图6),第二组分裂为一个只含3的组和一个含有11、27的组,但节点之间的相对顺序并未改变。这样在ReHash时,我们就不需要移动节点了。
实现细节
由于扩容时数组的复制会占用大量的时间,这里我们采用了将整个数组分块,懒惰建立的方法。这样,当访问到某下标时,仅需判断此下标所在块是否已建立完毕(如果没有则建立)。
另外定义size为当前已使用的下标范围,其初始值为2,数组扩容时仅需将size加倍即可;定义count代表目前HashMap中包含的总节点个数(不算哨兵节点)。
初始时,数组中除第0项外,所有项都为null。第0项指向一个仅有一个哨兵节点的链表,代表整条链的起点。初始时全貌见图7,其中浅绿色代表当前未使用的下标范围,虚线箭头代表逻辑上存在,但实际未建立的块。
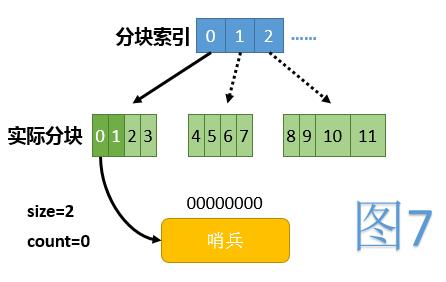
初始化下标操作
数组中为null的项都认为处于未初始化状态,初始化某个下标即代表建立其对应的哨兵节点。初始化是递归进行的,即若其父下标未初始化,则先初始化其父下标。(一个下标的父下标是其移除最高二进制位后得到的下标)大致代码如下:
private void initializeBucket(int bucketIdx) {
int parentIdx = bucketIdx ^ Integer.highestOneBit(bucketIdx);
if (getBucket(parentIdx) == null)
initializeBucket(parentIdx);
Node dummy = new Node();
dummy.hash = Integer.reverse(bucketIdx);
dummy.next = new AtomicReference<>();
setBucket(bucketIdx, listInsert(getBucket(parentIdx), dummy));
}
其中getBucket即封装过的获取数组某下标内容的方法,setBucket同理。listInsert将从指定位置开始查找适合插入的位置插入给定的节点,若链表中已存在hash相同的节点则返回那个已存在的节点;否则返回新插入的节点。
插入操作
- 首先用HashMap的size对键的hashCode取模,得到应插入的数组下标。
- 然后判断该下标处是否为null,如果为null则初始化此下标。
- 构造一个新的节点,并插入到适当位置,注意节点中的hash值应为原hashCode经过位翻转并将最低位置1之后的值。
- 将节点个数计数器加1,若加1后节点过多,则仅需将size改为size*2,代表对数组扩容(ReHash)。
查找操作
- 找出待查找节点在数组中的下标。
- 判断该下标处是否为null,如果为null则返回查找失败。
- 从相应位置进入链表,顺次寻找,直至找出待查找节点或超出本组节点范围。
删除操作
- 找出应删除节点在数组中的下标。
- 判断该下标处是否为null,如果为null则初始化此下标。
- 找到待删除节点,并从链表中删除。(注意由于哨兵节点的存在,任何正常元素只被其唯一的前驱节点所引用,不存在被前驱节点与数组中指针同时引用的情况,从而不会出现需要同时修改多个指针的情况)
- 将节点个数计数器减1。
参考文献
《Split-Ordered Lists: Lock-Free Extensible Hash Tables》
(全文完)


关注CoolShell微信公众账号和微信小程序
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)






 (30 人打了分,平均分: 3.40 )
(30 人打了分,平均分: 3.40 )
《无锁HashMap的原理与实现》的相关评论
沙发
沙发有屎,我坐板凳@Wiflg Goth
先占个座儿 。
这么晚发博客,辛苦了。
放pocket中,明天再看!失眠好多次~
put/delete操作至少三次cacheline访问,sizeIncrement和listInsert都是竞争热点。在非竞争下,性能差,激烈竞争时性能更差。
温少牛人啊,这么晚了还在学习。@温少
文中的图是用什么工具画的?
昨天我在阿里面试实习生被问的就是这个问题,我回答的就是用单链表的原子操作,不过rehash过程没能想到这么详细的方法,细节也不够,不知道面试能不能给过。
为什么不只判断size来进行CAS判断,这样的话,性能会好一些吧。
请问这个性能测试指标有哪些
用CAS也是要等的,不过好像粒度变小。不知实际性能咋样
@夕水溪下
学习浩哥精神,用ppt
博主所描述的无锁链表根本不可能实现,考虑这种情况:
A->B->C
线程1:尝试在B->C之间插入新节点D
线程2:尝试删除B
按照博主的方法将会出现这种情况:
A->C
↗
B->D
D节点被莫名其妙牺牲掉了
今天看到博主写这个主题我很高兴,因为我刚好以前写过一个和博主描述一模一样的HashMap。
我个人认为插入操作和删除操作不加锁是无法完成的(即put和remove)操作,就算不在整个HashMap上加锁,也要在节点上加锁。
本想看看博主会如何解决这个问题,但是很遗憾博主只是侧重在哈希扩容时的不加锁解决方案。不过也好啦,哈哈。
其实我写过的那个HashMap扩容和博主的基本一样,就是链表排序(之前我还考虑排序会不会影响效率,后来一想根本不会,因为put操作要把相关的节点全部遍历一遍才行,顺便就把应该插入的有序位置确定好了,根本不影响效率。)
此外,不用一整块数组,而是用多级数组来找,也是我写的那个HashMap的解决方法。不同于博主的两级,我写的允许多级。
另外一点就是我没有用哨兵节点,也没有要求整个HashMap的节点全部排序并连接成一条链表。
恕我愚昧,我不能理解博主为何要设置哨兵节点,并把所有链表连接成一条链表。我认为不这么做完全没有问题。
此外,我认为哈希扩容不论怎么减少时间,还是一个比较耗时的操作,且是一个频率发生不是很高的操作。因此,我认为在哈希扩容的时候锁定整个HashMap应该是没有什么关系的。
而且博主的解决方法也肯定必须让哈希扩容排斥另一个哈希扩容吧。(虽然可以令扩容期间put和remove操作照常进行。)
另外这篇文章又勾起了我之前的一个问题:
对于读-改-写这种操作,如何无锁又线程安全的实现。
我能想出的解决方法无非是自旋锁,或自旋锁的变种。
@mosky
设置哨兵节点,是为了防止某个数据节点被数组和前驱节点同时引用,这样删除它的时候需要同时更新两个指针(用CAS无法做到)。
文中所述的Hash扩展是懒惰的,它本质上只是对一个全局size变量所做的原子性加倍操作,不会耗时很多。另外,加倍时,如果CAS返回失败,则不会重新尝试加倍操作,防止重复加倍(这是你所说的排斥?).
关于有序链表的操作,文章所述确实存在一些疏漏,如需了解链表的严格操作方法,请参阅http://cs.brown.edu/~mph/HellerHLMSS05/2005-OPODIS-Lazy.pdf
其实我更关心的是这篇文章里的图是用什么软件画的,很带感的样子~~
唉,最近在苦逼论文,望陈皓能现身明示。
学习了,看了博主很多文章,你可真是全才啊。。。
@onetwogoo
感谢作者能解答这个问题。
现在有些理解哨兵节点,以及将所有链表练成一个链表的意义了。
我没有设置哨兵节点,也没有把链表连起来,于是在扩容的时候不得不使用锁来保证分链表的中间的插入操作不至于在扩容的时候发生错误。
如果设置了哨兵节点,则根本不必在此进行额外的锁操作。
我之前有做过个测试,600个线程用无锁的队列取东西,没见到比LinkedBlockingQueue快多少,可能还比他慢点。竞争激烈的时候,无锁还不如有锁。
需要实现无锁那就必须自锁,就像之前的那篇无锁队列http://coolshell.cn/articles/8239.html的插图,一辆自行车如果没有锁的话,那他需要自己把自己锁起来。
用原子操作在无竞争的情况下能提供效率,在有竞争的情况下并没有快多少。
针对map,如果是大量的写操作,那无论用什么方式都差不多,但是读的比例远高于写的比例的话,那就大有文章可做。可以想办法去除读取时所有与锁及原子操作的相关代码,大大提供读取时的效率。
为了达到这个目的,我也专门定制了一个map,只在添加(包含rehash)及删除时加锁。
需要注意的地方就时在rehash时不要影响原来的hash表,在链表中添加entry时添加在链表头,整个添加操作的最后再修改链表的root。当然这个方式在jdk1.4及之前由于内存无序写入的问题,会发生意料之外的问题。不过在jdk1.5及之后的版本已经修复了这个问题。
同意,文中谈到的无锁链表的删除是有问题的,误导读者,这有片详细的论文,实现无锁链表非阻塞删除
http://www.liblfds.org/mediawiki/images/1/1d/Valois_-_Lock-Free_Linked_Lists_Using_Compare-and-Swap.pdf
@Zealot
rehash只是再mod array 的 length么?
@温少
CAS也是性能杀手啊。实际性能有待测试!
我觉得把CAS不当成锁应该是不正确的,从广义角度来讲CAS也是锁的一种实现。其实底层并发控制也就那么些东西,CAS,轮询,进程/线程通信等。。。
赞!「无锁就意味着自锁」,真实现起来,要考虑周全相当费脑子啊…… 而且似乎没法测,只能用作证明题的思路证明正确性…… 另外,对于「除非修改两个指针否则无法做到一致性」这种硬件的原子操作难以完成的事情,似乎无解,比如双向链表……
@Zealot
博主讲述的无锁链表没有问题。你没有考虑到的情况是如果线程2执行成功,那么线程1每次自旋过程中都会去重新查找插入位置,也即文中的”Node a = findInsertionPlace(head),…”,所以你的前提”尝试在B->C之间插入新节点D”就有问题。通过findInsertionPlace(head)也能看出无锁自旋也是有代价的,是否适用得看具体场景。
我的理解是,新建这个Map的时候就可以指定好每个区块负责多少个实际分块,也就是说每个键值在put的时候就确定了,并且一直不会该改变
比如,当键值A的hashcode在11的位置,A在被put的时候就直接放在了11这个分块上,并且初始化2这个分块索引,1可以不用初始化。
直接说就是,通过分块索引的引入,避免了Rehash过程中结点的移动。
不知这样说 是否正确?
@你最红
前提并没有问题,假设线程1先findInsertionPlace(head)找到B,要在B后插入D了,但是还没插入完成的时候(B.next还未修改) 线程2执行了,利索地删除了B(结果为 A->C B->C, 这里改的是 A.next,B.next 不变),然后线程1继续执行插入,”成功”地插在了B后面(A->C B->D->C),并结束了循环,并没有重新遍历找插入位置。
如果没有删除,只有插入,上面的插入实现完美无缺,但是如果有删除,以上的实现就必然有问题。
因为删除过程中不可能知道有另一个线程已经准备好在当前要删除的节点后插入新节点了(完成插入前只是读取了链表的数据,没有在链表中留下任何信息,这是就目前的插入代码来说,当然可以添加这样的辅助信息让删除知道有这么个情况,比如用一个AtomicInteger记录当前进入插入流程的线程个数和删除流程线程的个数,可以设计成插入和删除在不同阶段交替执行,嗯,复杂化了,应该算馊主意,哈哈)。