性能测试应该怎么做?
 偶然间看到了阿里中间件Dubbo的性能测试报告,我觉得这份性能测试报告让人觉得做这性能测试的人根本不懂性能测试,我觉得这份报告会把大众带沟里去,所以,想写下这篇文章,做一点科普。
偶然间看到了阿里中间件Dubbo的性能测试报告,我觉得这份性能测试报告让人觉得做这性能测试的人根本不懂性能测试,我觉得这份报告会把大众带沟里去,所以,想写下这篇文章,做一点科普。
首先,这份测试报告里的主要问题如下:
1)用的全是平均值。老实说,平均值是非常不靠谱的。
2)响应时间没有和吞吐量TPS/QPS挂钩。而只是测试了低速率的情况,这是完全错误的。
3)响应时间和吞吐量没有和成功率挂钩。

 (72 人打了分,平均分: 4.56 )
(72 人打了分,平均分: 4.56 )| Refresh | This website coolshell.cn/page/7 is currently offline. Cloudflare's Always Online™ shows a snapshot of this web page from the Internet Archive's Wayback Machine. To check for the live version, click Refresh. |
偶然间看到了阿里中间件Dubbo的性能测试报告,我觉得这份性能测试报告让人觉得做这性能测试的人根本不懂性能测试,我觉得这份报告会把大众带沟里去,所以,想写下这篇文章,做一点科普。
首先,这份测试报告里的主要问题如下:
1)用的全是平均值。老实说,平均值是非常不靠谱的。
2)响应时间没有和吞吐量TPS/QPS挂钩。而只是测试了低速率的情况,这是完全错误的。
3)响应时间和吞吐量没有和成功率挂钩。
(72 人打了分,平均分: 4.56 ) 昨天,我看到一个新闻——雅虎取消了QA团队,工程师必须自己负责代码质量,并使用持续集成代替QA。 同时,也听到网友说,“听微软做数据库运维的工程师介绍,他们也是把运维工程师和测试工程师取消了,由开发全部完成。每个人都是全栈工程师”。于是,我顺势引用了几年前写过一篇文章《我们需要专职的QA吗?》,并且又鼓吹了一下全栈。当然,一如既往的得到了一些的争议和嘲弄;-)。
昨天,我看到一个新闻——雅虎取消了QA团队,工程师必须自己负责代码质量,并使用持续集成代替QA。 同时,也听到网友说,“听微软做数据库运维的工程师介绍,他们也是把运维工程师和测试工程师取消了,由开发全部完成。每个人都是全栈工程师”。于是,我顺势引用了几年前写过一篇文章《我们需要专职的QA吗?》,并且又鼓吹了一下全栈。当然,一如既往的得到了一些的争议和嘲弄;-)。
有人认为取消QA基本上是公司没钱的象征,这个观点根本不值一驳,属于井底之蛙。有人认为,社会分工是大前提,并批评我说怎么不说把所有的事全干的,把我推向了另外一个极端。另外,你千万不要以为有了分工,QA的工作就保得住了。
就像《乔布斯传》中乔布斯质疑财务制度的时候说的,有时候,很多人都不问为什么,觉得存在的东西都是理所应当的东西。让我们失去了独立思考的机会。分工也是一样。
所以,为了说完整分工这个逻辑。请大家耐住性子,让我就先来谈谈“分工的优缺点”吧。
(101 人打了分,平均分: 4.37 )(感谢网友 @我的上铺叫路遥 投稿)

对于海量数据处理业务,我们通常需要一个索引数据结构,用来帮助查询,快速判断数据记录是否存在,这种数据结构通常又叫过滤器(filter)。考虑这样一个场景,上网的时候需要在浏览器上输入URL,这时浏览器需要去判断这是否一个恶意的网站,它将对本地缓存的成千上万的URL索引进行过滤,如果不存在,就放行,如果(可能)存在,则向远程服务端发起验证请求,并回馈客户端给出警告。
索引的存储又分为有序和无序,前者使用关联式容器,比如B树,后者使用哈希算法。这两类算法各有优劣:比如,关联式容器时间复杂度稳定O(logN),且支持范围查询;又比如哈希算法的查询、增删都比较快O(1),但这是在理想状态下的情形,遇到碰撞严重的情况,哈希算法的时间复杂度会退化到O(n)。因此,选择一个好的哈希算法是很重要的。
时下一个非常流行的哈希索引结构就是bloom filter,它类似于bitmap这样的hashset,所以空间利用率很高。其独特的地方在于它使用多个哈希函数来避免哈希碰撞,如图所示(来源wikipedia),bit数组初始化为全0,插入x时,x被3个哈希函数分别映射到3个不同的bit位上并置1,查询x时,只有被这3个函数映射到的bit位全部是1才能说明x可能存在,但凡至少出现一个0表示x肯定不存在。
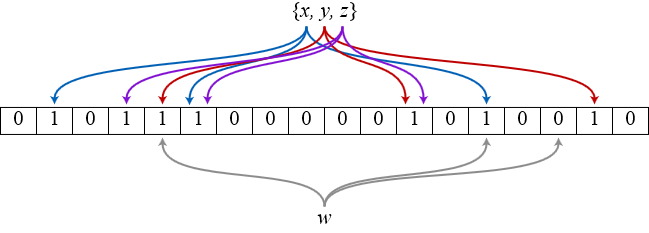
 (51 人打了分,平均分: 4.20 )
(51 人打了分,平均分: 4.20 ) 在上一篇介绍AUFS的文章中,大家可以看到,Docker的分层镜像是怎么通过UnionFS这种文件系统做到的,但是,因为Docker首选的AUFS并不在Linux的内核主干里,所以,对于非Ubuntu的Linux分发包,比如CentOS,就无法使用AUFS作为Docker的文件系统了。于是作为第二优先级的DeviceMapper就被拿出来做分层镜像的一个实现。
在上一篇介绍AUFS的文章中,大家可以看到,Docker的分层镜像是怎么通过UnionFS这种文件系统做到的,但是,因为Docker首选的AUFS并不在Linux的内核主干里,所以,对于非Ubuntu的Linux分发包,比如CentOS,就无法使用AUFS作为Docker的文件系统了。于是作为第二优先级的DeviceMapper就被拿出来做分层镜像的一个实现。
DeviceMapper自Linux 2.6被引入成为了Linux最重要的一个技术。它在内核中支持逻辑卷管理的通用设备映射机制,它为实现用于存储资源管理的块设备驱动提供了一个高度模块化的内核架构,它包含三个重要的对象概念,Mapped Device、Mapping Table、Target device。
Mapped Device 是一个逻辑抽象,可以理解成为内核向外提供的逻辑设备,它通过Mapping Table描述的映射关系和 Target Device 建立映射。Target device 表示的是 Mapped Device 所映射的物理空间段,对 Mapped Device 所表示的逻辑设备来说,就是该逻辑设备映射到的一个物理设备。
Mapping Table里有 Mapped Device 逻辑的起始地址、范围、和表示在 Target Device 所在物理设备的地址偏移量以及Target 类型等信息(注:这些地址和偏移量都是以磁盘的扇区为单位的,即 512 个字节大小,所以,当你看到128的时候,其实表示的是128*512=64K)。
(40 人打了分,平均分: 3.95 ) AUFS是一种Union File System,所谓UnionFS就是把不同物理位置的目录合并mount到同一个目录中。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合 mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。
AUFS是一种Union File System,所谓UnionFS就是把不同物理位置的目录合并mount到同一个目录中。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合 mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。
AUFS又叫Another UnionFS,后来叫Alternative UnionFS,后来可能觉得不够霸气,叫成Advance UnionFS。是个叫Junjiro Okajima(岡島順治郎)在2006年开发的,AUFS完全重写了早期的UnionFS 1.x,其主要目的是为了可靠性和性能,并且引入了一些新的功能,比如可写分支的负载均衡。AUFS在使用上全兼容UnionFS,而且比之前的UnionFS在稳定性和性能上都要好很多,后来的UnionFS 2.x开始抄AUFS中的功能。但是他居然没有进到Linux主干里,就是因为Linus不让,基本上是因为代码量比较多,而且写得烂(相对于只有3000行的union mount和10000行的UnionFS,以及其它平均下来只有6000行代码左右的VFS,AUFS居然有30000行代码),所以,岡島不断地改进代码质量,不断地提交,不断地被Linus拒掉,所以,到今天AUFS都还进不了Linux主干(今天你可以看到AUFS的代码其实还好了,比起OpenSSL好N倍,要么就是Linus对代码的质量要求非常高,要么就是Linus就是不喜欢AUFS)。
不过,好在有很多发行版都用了AUFS,比如:Ubuntu 10.04,Debian6.0, Gentoo Live CD支持AUFS,所以,也OK了。
好了,扯完这些闲话,我们还是看一个示例吧(环境:Ubuntu 14.04)
(40 人打了分,平均分: 4.18 ) 前面,我们介绍了Linux Namespace,但是Namespace解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离。也就是说,虽然你通过Namespace把我Jail到一个特定的环境中去了,但是我在其中的进程使用用CPU、内存、磁盘等这些计算资源其实还是可以随心所欲的。所以,我们希望对进程进行资源利用上的限制或控制。这就是Linux CGroup出来了的原因。
前面,我们介绍了Linux Namespace,但是Namespace解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离。也就是说,虽然你通过Namespace把我Jail到一个特定的环境中去了,但是我在其中的进程使用用CPU、内存、磁盘等这些计算资源其实还是可以随心所欲的。所以,我们希望对进程进行资源利用上的限制或控制。这就是Linux CGroup出来了的原因。
Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。这个项目最早是由Google的工程师在2006年发起(主要是Paul Menage和Rohit Seth),最早的名称为进程容器(process containers)。在2007年时,因为在Linux内核中,容器(container)这个名词太过广泛,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中去。然后,其它开始了他的发展。
Linux CGroupCgroup 可让您为系统中所运行任务(进程)的用户定义组群分配资源 — 比如 CPU 时间、系统内存、网络带宽或者这些资源的组合。您可以监控您配置的 cgroup,拒绝 cgroup 访问某些资源,甚至在运行的系统中动态配置您的 cgroup。
主要提供了如下功能:
(67 人打了分,平均分: 4.28 ) 时下最热的技术莫过于Docker了,很多人都觉得Docker是个新技术,其实不然,Docker除了其编程语言用go比较新外,其实它还真不是个新东西,也就是个新瓶装旧酒的东西,所谓的The New “Old Stuff”。Docker和Docker衍生的东西用到了很多很酷的技术,我会用几篇 文章来把这些技术给大家做个介绍,希望通过这些文章大家可以自己打造一个山寨版的docker。
时下最热的技术莫过于Docker了,很多人都觉得Docker是个新技术,其实不然,Docker除了其编程语言用go比较新外,其实它还真不是个新东西,也就是个新瓶装旧酒的东西,所谓的The New “Old Stuff”。Docker和Docker衍生的东西用到了很多很酷的技术,我会用几篇 文章来把这些技术给大家做个介绍,希望通过这些文章大家可以自己打造一个山寨版的docker。
当然,文章的风格一定会尊重时下的“流行”——我们再也没有整块整块的时间去看书去专研,而我们只有看微博微信那样的碎片时间(那怕我们有整块的时间,也被那些在手机上的APP碎片化了)。所以,这些文章的风格必然坚持“马桶风格”(希望简单到占用你拉一泡屎就时间,而且你还不用动脑子,并能学到些东西)
废话少说,我们开始。先从Linux Namespace开始。
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。不知道你是否还记得很早以前的Unix有一个叫chroot的系统调用(通过修改根目录把用户jail到一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。
(105 人打了分,平均分: 4.54 ) 在 Docker基础技术:Linux Namespace(上篇)中我们了解了,UTD、IPC、PID、Mount 四个namespace,我们模仿Docker做了一个相当相当山寨的镜像。在这一篇中,主要想向大家介绍Linux的User和Network的Namespace。
在 Docker基础技术:Linux Namespace(上篇)中我们了解了,UTD、IPC、PID、Mount 四个namespace,我们模仿Docker做了一个相当相当山寨的镜像。在这一篇中,主要想向大家介绍Linux的User和Network的Namespace。
好,下面我们就介绍一下还剩下的这两个Namespace。
User Namespace主要是用了CLONE_NEWUSER的参数。使用了这个参数后,内部看到的UID和GID已经与外部不同了,默认显示为65534。那是因为容器找不到其真正的UID所以,设置上了最大的UID(其设置定义在/proc/sys/kernel/overflowuid)。
要把容器中的uid和真实系统的uid给映射在一起,需要修改 /proc/<pid>/uid_map 和 /proc/<pid>/gid_map 这两个文件。这两个文件的格式为:
ID-inside-ns ID-outside-ns length
其中:
(40 人打了分,平均分: 4.33 ) 今天,在微博上看了一篇《微信和淘宝到底是谁封谁》的文章,我觉得文章中逻辑错乱,所以,我发了一篇关于这篇文章逻辑问题的长微博。后面,我被原博主冷嘲热讽了一番,说是什么鸡汤啊,什么我与某某之流的人在一起混淆视听啊,等等。并且也有一些网友找我讨论一下相关的钓鱼式攻击的技术问题。所以,我想写下这篇纯技术文章,因为我对那些商业利益上的东西不关心,所以,只谈技术,这样最简单。
今天,在微博上看了一篇《微信和淘宝到底是谁封谁》的文章,我觉得文章中逻辑错乱,所以,我发了一篇关于这篇文章逻辑问题的长微博。后面,我被原博主冷嘲热讽了一番,说是什么鸡汤啊,什么我与某某之流的人在一起混淆视听啊,等等。并且也有一些网友找我讨论一下相关的钓鱼式攻击的技术问题。所以,我想写下这篇纯技术文章,因为我对那些商业利益上的东西不关心,所以,只谈技术,这样最简单。
首先说明一下,我个人不是一个安全专家,也不是一个移动开发专家,按道理来说,这篇文章不应该我来写,但是我就试一试,请原谅我的无知,也期待抛砖引玉了,希望安全的同学斧正。
关于钓鱼式攻击,其实是通过一种社会工程学的方式来愚弄用户的攻击式,攻击者通常会模仿一个用户信任的网站来偷取用户的机密信息,比如用户密码或是信用卡。一般来说,攻击者会通过邮件和实时通信工具完成,给被攻击者发送一个高仿的网站,然后让用户看不出来与正统网站的差别,然后收集用户的机密数据。
因为钓鱼式攻击并不新鲜,所以我这里只讲移动方面的。
在移动端,这个事情会更容易干,因为移动端有如下特点:
下面我们来分析下移动端的用户操作,我们重点关注用户控制权的切换过程(因为这是攻击点)
(64 人打了分,平均分: 4.44 )(感谢网友 @我的上铺叫路遥 投稿)
Linus大神又在rant了!这次的吐槽对象是时下很火热的并行技术(parellism),并直截了当地表示并行计算是浪费所有人时间(“The whole “let’s parallelize” thing is a huge waste of everybody’s time.”)。大致意思是说乱序性能快、提高缓存容量、降功耗。当然笔者不打算正面讨论并行的是是非非(过于宏伟的主题),因为Linus在另一则帖子中举了对象引用计数(reference counting)的例子来说明并行的复杂性。
在Linus回复之前有人指出对象需要锁机制的情况下,引用计数的原子性问题:
Since it is being accessed in a multi-threaded way, via multiple access paths, generally it needs its own mutex — otherwise, reference counting would not be required to be atomic and a lock of a higher-level object would suffice.
由于(对象)通过多线程方式及多种获取渠道,一般而言它需要自身维护一个互斥锁——否则引用计数就不要求是原子的,一个更高层次的对象锁足矣。
而Linus不那么认为:
The problem with reference counts is that you often need to take them *before* you take the lock that protects the object data.
引用计数的问题在于你经常需要在对象数据上锁保护之前完成它。
The thing is, you have two different cases:
问题有两种情况:
– object *reference* 对象引用
– object data 对象数据
and they have completely different locking.
它们锁机制是完全不一样的。
(42 人打了分,平均分: 3.83 )